|
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints Proc. of the European Conference on Computer Vision 2022
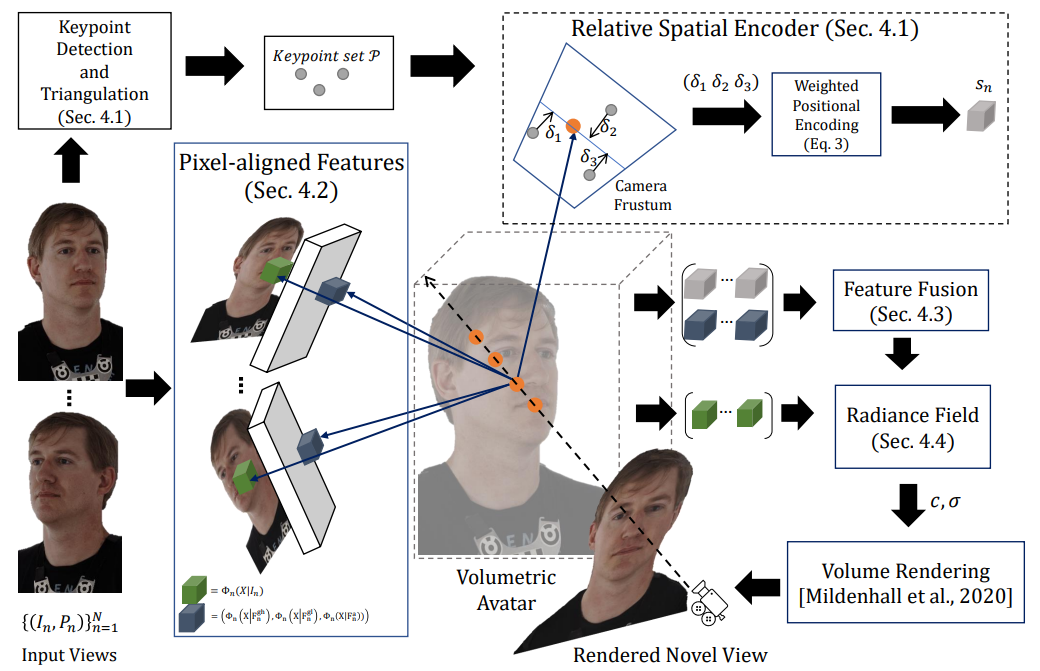
Abstract: Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior art that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling. Downloads:
Videos:
|