
|
Drivable 3D Gaussian Avatars W. Zielonka T. Bagautdinov S. Saito M. Zollhöfer J. Thies J. Romero arXiv 2023 We present a 3D controllable model for human bodies rendered with Gaussian splats. [paper] [video] [bibtex] [project] |

|
HybridNeRF: Efficient Neural Rendering via Adaptive Volumetric Surfaces H. Turki V. Agrawal S. R. Bulò L. Porzi P. Kontschieder D. Ramanan M. Zollhöfer C. Richardt arXiv 2023 We propose a hybrid neural rendering approach that renders most objects as surfaces while modeling the (typically) small fraction of challenging regions volumetrically. [paper] [video] [bibtex] [project] |

|
SpecNeRF: Gaussian Directional Encoding for Specular Reflections L. Ma V. Agrawal H. Turki C. Kim C. Gao P. V. Sander M. Zollhöfer C. Richardt arXiv 2023 We propose an approach to improve the modeling of challenging specular reflections in neural radiance fields. [paper] [video] [bibtex] [project] |

|
SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes E. Tretschk V. Golyanik M. Zollhöfer A. Bozic C. Lassner C. Theobalt Proc. of the International Conference on 3D Vision 2024 — 3DV 2024 We propose a dynamic-NeRF method for the reconstruction of general deforming scenes. [paper] [video] [bibtex] [project] |

|
A Local Appearance Model for Volumetric Capture of Diverse Hairstyles Z. Wang G. Nam A. Bozic C. Cao J. Saragih M. Zollhöfer J. Hodgins Proc. of the International Conference on 3D Vision 2024 — 3DV 2024 We propose an approach for creating high-fidelity avatars with diverse hairstyles. [paper] [bibtex] [project] |

|
PyNeRF: Pyramidal Neural Radiance Fields H. Turki M. Zollhöfer C. Richardt D. Ramanan Conference on Neural Information Processing Systems 2023 — NeurIPS 2023 We present an approach for scale-aware rendering of neural radiance fields. [paper] [video] [code] [bibtex] [project] |

|
VR-NeRF: High-Fidelity Virtualized Walkable Spaces L. Xu V. Agrawal W. Laney T. Garcia A. Bansal C. Kim S. R. Bulò L. Porzi P. Kontschieder A. Boži? D. Lin M. Zollhöfer C. Richardt ACM Transactions on Graphics 2023 (TOG) — Siggraph Asia 2023 We present an approach for the high-fidelity capture, model reconstruction, and real-time rendering of walkable spaces in VR. [paper] [video] [data] [bibtex] [project] |

|
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering L. Lyu A. Tewari M. Habermann S. Saito M. Zollhöfer T. Leimkuehler C. Theobalt ACM Transactions on Graphics 2023 (TOG) — Siggraph Asia 2023 We build a prior of natural illumination using a diffusion model and apply it to inverse renering. [paper] [video] [bibtex] [project] |

|
HDHumans: A Hybrid Approach for High-fidelity Digital Humans M. Habermann L. Liu W. Xu G. Pons-Moll M. Zollhöfer C. Theobalt Eurographics Symposium on Computer Animation — SCA 2023 We a method for HD human character synthesis that produces temporally coherent 3D surface [paper] [video] [bibtex] [project] |

|
HyperReel: High-Fidelity 6-DoF Video with Ray-Conditioned Sampling B. Attal J.-B. Huang C. Richardt M. Zollhöfer J. Kopf M. O'Toole C. Kim Proc. Computer Vision and Pattern Recognition 2023 — CVPR 2023 We propose a novel 6-DoF neural video approach that renders at real-time rates. [paper] [video] [bibtex] [project] |

|
NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation Z. Wang G. Nam T. Stuyck S. Lombardi C. Cao J. Saragih M. Zollhöfer J. Hodgins C. Lassner Proc. Computer Vision and Pattern Recognition 2023 — CVPR 2023 We present a two-stage approach that models hair independently from the head. [paper] [video] [bibtex] [project] |

|
Neural Pixel Composition: 3D-4D View Synthesis from Multi-Views A. Bansal M. Zollhöfer Proc. Computer Vision and Pattern Recognition 2023 — CVPR 2023 We present a novel approach for continuous 3D-4D view synthesis. [paper] [video] [bibtex] [project] |

|
AdaNeRF: Adaptive Sampling for Real-time Rendering of Neural Radiance Fields A. Kurz T. Neff Z. Lv M. Zollhöfer M. Steinberger Proc. of the European Conference on Computer Vision 2022 — ECCV 2022 We propose a novel neural rendering architecture that learns an efficient sampling strategy. [paper] [video] [bibtex] [project] |

|
TAVA: Template-free Animatable Volumetric Actors R. Li J. Tanke M. Vo M. Zollhöfer J. Gall A. Kanazawa C. Lassner European Conference on Computer Vision 2022 — ECCV 2022 We propose a method to create volumatric animatable models of humans. [paper] [video] [bibtex] [project] |

|
KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints M. Mihajlovic A. Bansal M. Zollhöfer S. Tang S. Saito Proc. of the European Conference on Computer Vision 2022 — ECCV 2022 We propose an approach for modeling high-fidelity volumetric avatars from sparse views. [paper] [video] [bibtex] [project] |

|
AutoAvatar: Autoregressive Neural Fields for Dynamic Avatar Modeling Z. Bai T. Bagautdinov J. Romero M. Zollhöfer P. Tan S. Saito Proc. of the European Conference on Computer Vision 2022 — ECCV 2022 We employ autoregressive modeling for building dynamic avatars. [paper] [video] [bibtex] [project] |

|
Mutual Scene Synthesis for Mixed Reality Telepresence M. Keshavarzi M. Zollhöfer Allen Y.Yang Patrick Peluse Luisa Caldas arXiv 2022 Our method generates a mutually and physically accessible scene for several mixed-reality users [paper] [bibtex] [project] |

|
Authentic Volumetric Avatars From a Phone Scan C. Cao T. Simon G. Schwartz M. Zollhöfer S. Saito S. Lombardi S. Wei D. Belko S. Yu Y. Sheikh J. Saragih ACM Transactions on Graphics 2022 (TOG) — Siggraph 2022 We create lifelike avatars of people given a short phone scan. [paper] [video] [project] |

|
iSDF: Real-Time Neural Signed Distance Fields for Robot Perception J. Ortiz A. Clegg J. Dong E. Sucar D. Novotny M. Zollhöfer M. Mukadam Robotics: Science and Systems — RSS 2022 We present iSDF, a continual learning system for real-time signed distance field (SDF) reconstruction. [paper] [video] [code] [bibtex] [project] |

|
Self-supervised Neural Articulated Shape and Appearance Models F. Wei R. Chabra L. Ma C. Lassner M. Zollhöfer S. Rusinkiewicz C. Sweeney R. Newcombe M. Slavcheva Proc. Computer Vision and Pattern Recognition 2022 — CVPR 2022 (Poster) Our novel representation learns shape, appearance, and articulation codes that enable independent control of these semantic dimensions. [paper] [video] [bibtex] [project] |
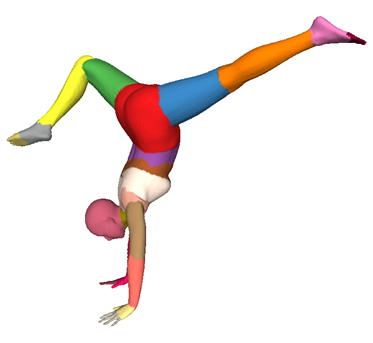
|
COAP: Compositional Articulated Occupancy of People M. Mihajlovic S. Saito A. Bansal M. Zollhöfer S. Tang Proc. Computer Vision and Pattern Recognition 2022 — CVPR 2022 (Poster) We present a novel neural implicit representation for articulated human bodies. [paper] [video] [bibtex] [project] |

|
Neural 3D Video Synthesis T. Li M. Slavcheva M. Zollhöfer S. Green C. Lassner C. Kim T. Schmidt S. Lovegrove M. Goesele Z. Lv Proc. Computer Vision and Pattern Recognition 2022 — CVPR 2022 (Oral) We propose a novel approach for 3D video synthesis that enables high-quality view synthesis and motion interpolation. [paper] [video] [bibtex] [project] |

|
HVH: Learning a Hybrid Neural Volumetric Representation for Dynamic Hair Performance Capture Z. Wang G. Nam T. Stuyck S. Lombardi M. Zollhöfer J. Hodgins C. Lassner Proc. Computer Vision and Pattern Recognition 2022 — CVPR 2022 (Poster) We propose a novel representation for neural rendering of hair that is composed of thousands of primitives [paper] [video] [bibtex] [project] |

|
Learning Neural Light Fields with Ray-Space Embedding Networks B. Attal J.-B. Huang M. Zollhöfer J. Kopf C. Kim Proc. Computer Vision and Pattern Recognition 2022 — CVPR 2022 (Poster) We propose a novel neural light field representation that is compact and directly predicts integrated radiance along rays. [paper] [supplemental] [video] [bibtex] [project] |
|
Advances in Neural Rendering A. Tewari J. Thies B. Mildenhall P. Srinivasan E. Tretschk Y. Wang C. Lassner V. Sitzmann R. Martin-Brualla S. Lombardi T. Simon C. Theobalt M. Nießner J.T. Barron G. Wetzstein M. Zollhöfer V. Golyanik Computer Graphics Forum 2022 — EG 2022 (STAR Report) This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. [paper] [bibtex] [project] |

|
A-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering S-Y. Su F. Yu M. Zollhöfer H. Rhodin Conference on Neural Information Processing Systems 2021 — NeurIPS 2021 We propose a novel test-time optimization approach for monocular motion capture that learns a volumetric body model of the user in a self-supervised manner. [paper] [bibtex] [project] |

|
MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement A. Richard M. Zollhöfer Y. Wen F. Torre Y. Sheikh Proc. of the International Conference on Computer Vision 2021 — ICCV 2021 (Poster) We propose a generic audio-driven facial animation approach that achieves highly realistic motion synthesis results for the entire face. [paper] [video] [bibtex] [project] |
|
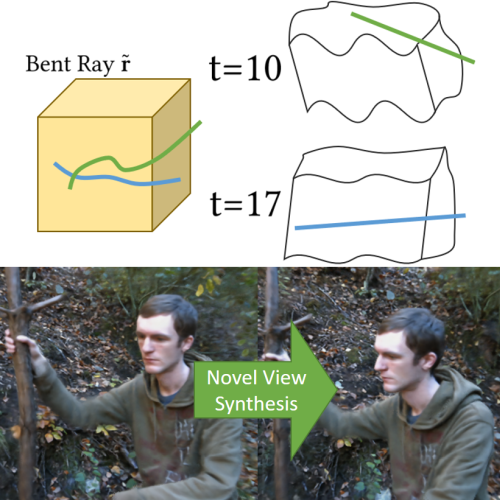
Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Deforming Scene from Monocular Video E. Tretschk A. Tewari V. Golyanik M. Zollhöfer C. Lassner C. Theobalt Proc. of the International Conference on Computer Vision 2021 — ICCV 2021 (Poster) In this tech report, we present the current state of our ongoing work on reconstructing Neural Radiance Fields (NERF) of general non-rigid scenes via ray bending. [paper] [video] [code] [bibtex] [project] |

|
A Deeper Look into DeepCap M. Habermann W. Xu M. Zollhöfer G. Pons-Moll C. Theobalt Transactions on Pattern Analysis and Machine Intelligence — TPAMI 2021 This work is an extended version of DeepCap where we provide more detailed explanations, comparisons and results as well as applications. [paper] [video] [data] [bibtex] [project] |

|
Real-time Deep Dynamic Characters M. Habermann L. Liu W. Xu M. Zollhöfer G. Pons-Moll C. Theobalt ACM Transactions on Graphics 2021 (TOG) — Siggraph 2021 We propose a deep videorealistic 3D human character model displaying highly realistic shape, motion, and dynamic appearance learned in a new weakly supervised way from multi-view imagery. [paper] [video] [bibtex] [project] |

|
Mixture of Volumetric Primitives for Efficient Neural Rendering S. Lombardi T. Simon G. Schwartz M. Zollhöfer Y. Sheikh J. Saragih ACM Transactions on Graphics 2021 (TOG) — Siggraph 2021 We present Mixture of Volumetric Primitives(MVP), a representation for rendering dynamic 3D content that combines the completeness of volumetric representations with the efficiency of primitive-based rendering. [paper] [video] [bibtex] [project] |

|
PVA: Pixel-aligned Volumetric Avatars A. Raj M. Zollhöfer T. Simon J. Saragih S. Saito J. Hays S. Lombardi Proc. Computer Vision and Pattern Recognition 2021 — CVPR 2021 (Poster) We devise a novel approach for predicting volumetric avatars that combines neural radiance fields with local, pixel-aligned features [paper] [video] [bibtex] [project] |

|
Pulsar: Efficient Sphere-based Neural Rendering C. Lassner M. Zollhöfer Proc. Computer Vision and Pattern Recognition 2021 — CVPR 2021 (Oral) We propose Pulsar, an efficient sphere-based differentiable renderer that is orders of magnitude faster than competing techniques, modular, and easy-to-use due to its tight integration with PyTorch. [paper] [bibtex] [project] |

|
Learning Compositional Radiance Fields of Dynamic Human Heads Z. Wang T. Bagautdinov S. Lombardi T. Simon J. Saragih J. Hodgins M. Zollhöfer Proc. Computer Vision and Pattern Recognition 2021 — CVPR 2021 (Oral) We bridge the gap between discrete and continuous volumetric representations by combining a coarse 3D-structure-aware grid with a continuous learned scene function. [paper] [video] [bibtex] [project] |

|
Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction G. Gafni J. Thies M. Zollhöfer M. Nießner Proc. Computer Vision and Pattern Recognition 2021 — CVPR 2021 (Oral) We present dynamic neural radiance fields for modeling the appearance and dynamics of a human face. [paper] [video] [bibtex] [project] |

|
Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction A. Bozic P. Palafox M. Zollhöfer J. Thies A. Dai M. Nießner Proc. Computer Vision and Pattern Recognition 2021 — CVPR 2021 (Oral) We introduce Neural Deformation Graphs for globally-consistent deformation tracking and 3D reconstruction of non-rigid objects. [paper] [video] [bibtex] [project] |

|
Thallo – Scheduling for High-Performance Large-scale Non-linear Least-Squares Solvers M. Mara M. Zollhöfer F. Heide M. Nießner P. Hanrahan ACM Transactions on Graphics 2021 (TOG) — Siggraph 2021 We propose Thallo, a domain-specific language for large-scale non-linear least squares optimization problems. [paper] [code] [bibtex] [project] |

|
Real-time Global Illumination Decomposition of Videos A. Meka M. Shafiei M. Zollhöfer C. Richardt C. Theobalt ACM Transactions on Graphics 2021 (TOG) — Siggraph 2021 We propose the first approach for the decomposition of a monocular color video into direct and indirect illumination components in real-time. [paper] [supplemental] [video] [bibtex] [project] |
|
3D Morphable Face Models - Past, Present and Future B. Egger W. A.P. Smith A. Tewari S. Wuhrer M. Zollhöfer T. Beeler F. Bernard T. Bolkart A. Kortylewski S. Romdhani C. Theobalt V. Blanz T. Vetter ACM Transactions on Graphics 2020 (TOG) — Siggraph 2021 In this paper, we provide a detailed survey of 3D Morphable Face Models over the 20 years since they were first proposed. [paper] [bibtex] [project] |
|
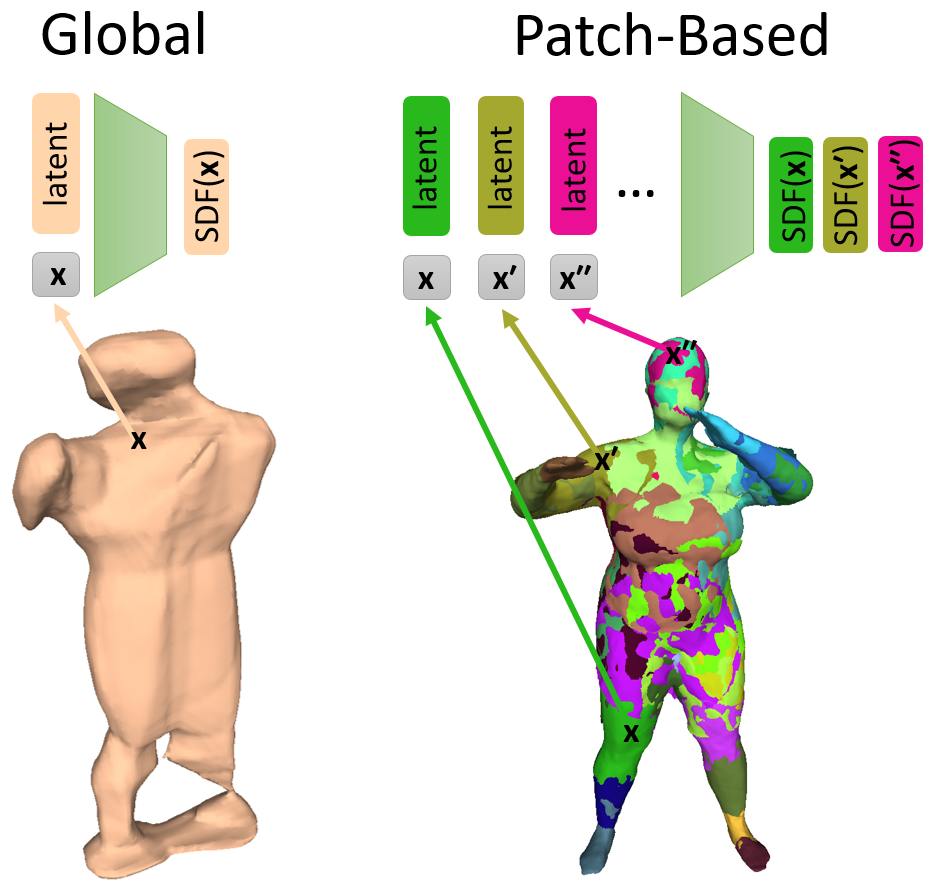
PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations E. Tretschk A. Tewari V. Golyanik M. Zollhöfer C. Stoll C. Theobalt European Conference on Computer Vision 2020 — ECCV 2020 We present a new mid-level patch-based surface representation. At the level of patches, objects across different categories share similarities, which leads to more generalizable models. [paper] [supplemental] [video] [talk] [bibtex] [project] |

|
State of the Art on Neural Rendering A. Tewari O. Fried J. Thies V. Sitzmann S. Lombardi K. Sunkavalli R. Martin-Brualla T. Simon J. Saragih M. Nießner R. Pandey S. Fanello G. Wetzstein J.-Y. Zhu C. Theobalt M. Agrawala E. Shechtman B. Goldman M. Zollhöfer Computer Graphics Forum 2020 — EG 2020 (STAR Report) This state-of-the-art report summarizes recent trends in neural rendering and discusses its applications [paper] [bibtex] [project] |

|
Neural Non Rigid Tracking A. Bozic P. Palafox M. Zollhöfer A. Dai J. Thies M. Nießner Proc. Neural Information Processing Systems 2020 — NeurIPS 2020 We introduce a novel, end-to-end learnable, differentiable non-rigid tracker that enables state-of-the-art non-rigid reconstruction. [paper] [video] [bibtex] [project] |
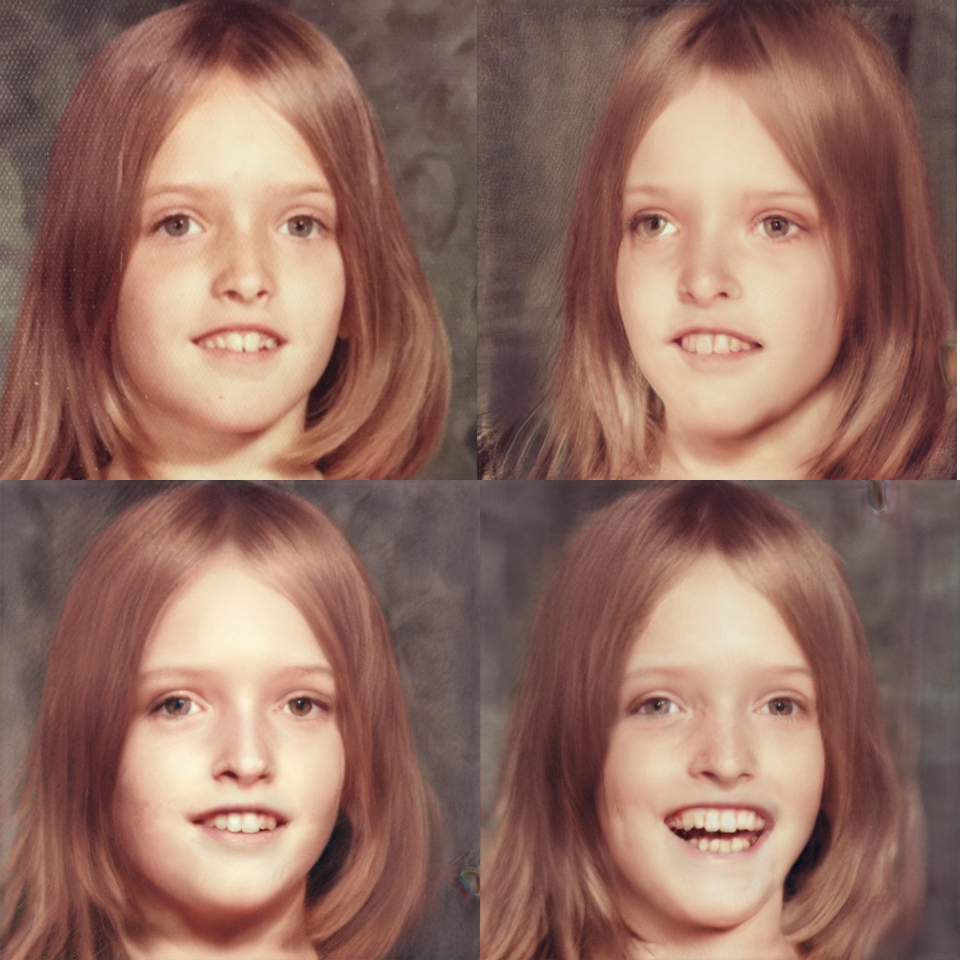
|
PIE: Portrait Image Embedding for Semantic Control A. Tewari M. Elgharib M. BR F. Bernard H-P. Seidel P. Perez M. Zollhöfer C. Theobalt ACM Transactions on Graphics 2020 (TOG) — SIGGRAPH Asia 2020 We present the first approach for embedding real portrait images in the latent space of StyleGAN which allows for intuitive editing of the head pose, facial expression, and scene illumination in the image. [paper] [supplemental] [video] [bibtex] [project] |
|
DEMEA: Deep Mesh Autoencoders for Non-Rigidly Deforming Objects E. Tretschk A. Tewari M. Zollhöfer V. Golyanik C. Theobalt European Conference on Computer Vision 2020 — ECCV 2020 (Spotlight) We propose a general-purpose DEep MEsh Autoencoder (DEMEA) which adds a novel embedded deformation layer to a graph-convolutional mesh autoencoder. [paper] [supplemental] [video] [talk] [bibtex] [project] |

|
DeepCap: Monocular Human Performance Capture Using Weak Supervision M. Habermann W. Xu M. Zollhöfer G. Pons-Moll C. Theobalt Proc. Computer Vision and Pattern Recognition 2020 — CVPR 2020 (Oral) We propose a novel deep learning approach for monocular dense human performance capture that is trained in a weakly supervised manner based on multi-view supervision. [paper] [video] [bibtex] [project] |

|
StyleRig: Rigging StyleGAN for 3D Control over Portrait Images A. Tewari M. Elgharib G. Bharaj F. Bernard H-P. Seidel P. Perez M. Zollhöfer C. Theobalt Proc. Computer Vision and Pattern Recognition 2020 — CVPR 2020 (Oral) We present the first method to provide a face rig-like control over a pretrained and fixed StyleGAN via a 3DMM. [paper] [supplemental] [video] [bibtex] [project] |
|
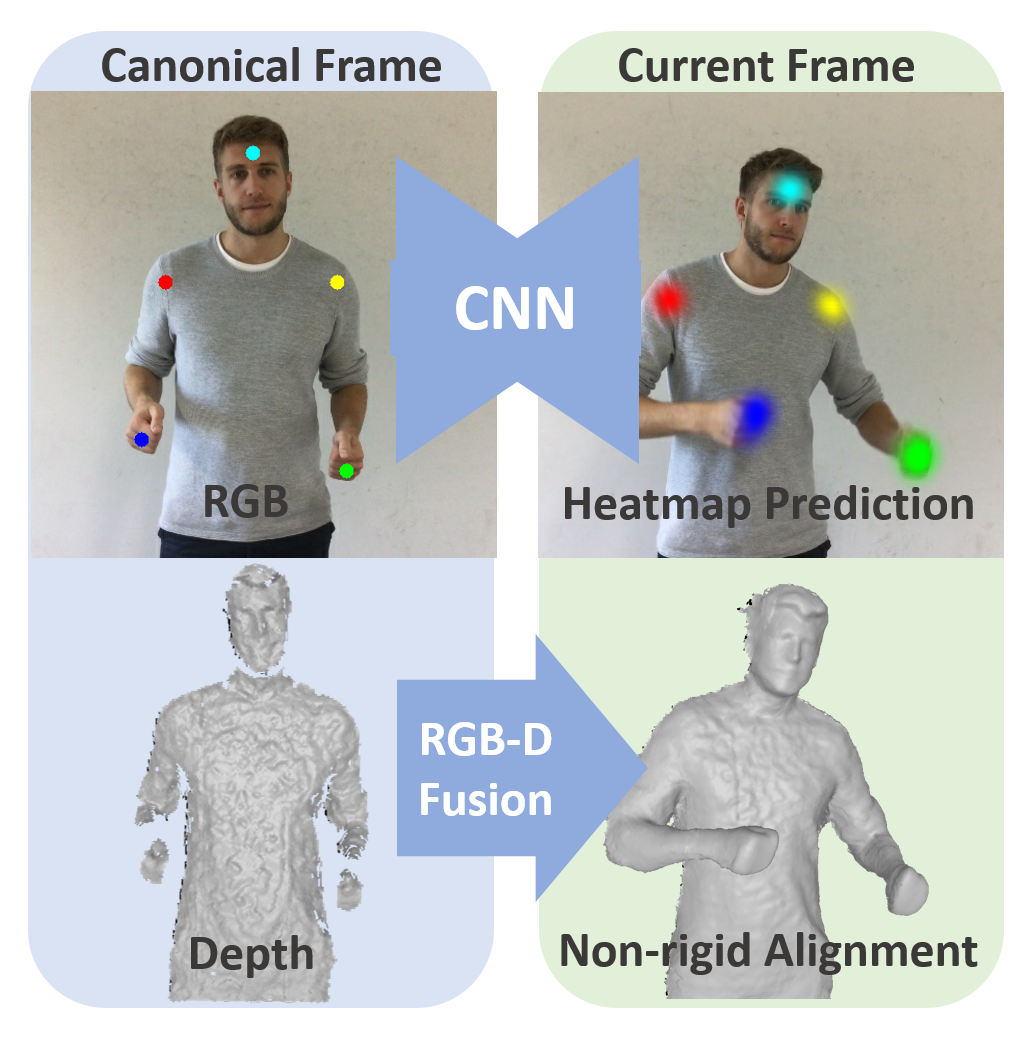
DeepDeform: Learning Non-rigid RGB-D Reconstruction with Semi-supervised Data A. Bozic M. Zollhöfer C. Theobalt M. Nießner Proc. Computer Vision and Pattern Recognition 2020 — CVPR 2020 We introduce a data-driven non-rigid feature matching approach, which we integrate into an optimization-based reconstruction pipeline. [paper] [video] [data] [bibtex] [project] |

|
Neural Human Video Rendering: Joint Learning of Dynamic Textures and Rendering-to-Video Translation L. Liu W. Xu M. Habermann M. Zollhöfer F. Bernard H. Kim W. Wang C. Theobalt IEEE Transactions on Visualization and Computer Graphics 2020 — TVCG 2020 In this paper, we propose a novel human video synthesis method that explicitly disentangles the learning of time-coherent fine-scale details from the embedding of the human in 2D screen space. [paper] [video] [bibtex] [project] |

|
IGNOR: Image-guided Neural Object Rendering J. Thies M. Zollhöfer C. Theobalt M. Stamminger M. Nießner International Conference on Learning Representations — ICLR 2020 We propose a new learning-based novel view synthesis approach for scanned objects that is trained based on a set of multi-view images. [paper] [video] [bibtex] [project] |

|
Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations V. Sitzmann M. Zollhöfer G. Wetzstein Conference on Neural Information Processing Systems 2019 — NeurIPS 2019 (Oral) We propose Scene Representation Networks (SRNs), a continuous, 3D-structure-aware scene representation that encodes both geometry and appearance. [paper] [video] [data] [code] [bibtex] [project] |

|
Neural Style-Preserving Visual Dubbing H. Kim M. Elgharib M. Zollhöfer H-P. Seidel T. Beeler C. Richardt C. Theobalt ACM Transactions on Graphics 2019 (TOG) — Siggraph Asia 2019 We present a style-preserving visual dubbing approach from single video inputs, which maintains the signature style of target actors. [paper] [video] [bibtex] [project] |

|
Text-based Editing of Talking-head Video O. Fried A. Tewari M. Zollhöfer A. Finkelstein E. Shechtman D. B. Goldman K. Genova Z. Jin C. Theobalt M. Agrawala ACM Transactions on Graphics 2019 (TOG) — Siggraph 2019 We propose a novel method to edit talking-head video based on its transcript to produce a realistic output video in which the dialogue of the speaker has been modified. [paper] [video] [data] [bibtex] [project] |

|
Deep Reflectance Fields A. Meka C. Haene R. Pandey M. Zollhöfer S. Fanello G. Fyffe A. Kowdle X. Yu J. Busch J. Dourgarian P. Denny S. Bouaziz P. Lincoln M. Whalen G. Harvey J. Taylor S. Izadi A. Tagliasacchi P. Debevec C. Theobalt J. Valentin C. Rhemann ACM Transactions on Graphics 2019 (TOG) — Siggraph 2019 We introduce the first system that combines the ability to deal with dynamic performances to the realism of 4D reflectance fields, enabling photo-realistic relighting of non-static faces. [paper] [video] [talk] [bibtex] [project] |

|
Deferred Neural Rendering: Image Synthesis using Neural Textures J. Thies M. Zollhöfer M. Nießner ACM Transactions on Graphics 2019 (TOG) — Siggraph 2019 Neural textures can be utilized to coherently re-render or manipulate existing video content in both static and dynamic environments at real-time rates. [paper] [video] [talk] [bibtex] [project] |

|
FML: Face Model Learning from Videos A. Tewari F. Bernard P. Garrido G. Bharaj M. Elgharib H-P. Seidel P. Perez M. Zollhöfer C. Theobalt Proc. Computer Vision and Pattern Recognition 2019 — CVPR 2019 (Oral) We propose multi-frame video-based self-supervised training of a deep network that learns a face identity model both in shape and appearance while jointly learning to reconstruct 3D faces. [paper] [supplemental] [video] [data] [talk] [bibtex] [project] |

|
DeepVoxels: Learning Persistent 3D Feature Embeddings V. Sitzmann J. Thies F. Heide M. Nießner G. Wetzstein M. Zollhöfer Proc. Computer Vision and Pattern Recognition 2019 — CVPR 2019 (Oral) In this work, we address the lack of 3D understanding of generative neural networks by introducing a persistent 3D feature embedding for view synthesis. [paper] [supplemental] [video] [code] [talk] [bibtex] [project] |

|
Neural Rendering and Reenactment of Human Actor Videos L. Liu W. Xu M. Zollhöfer H. Kim F. Bernard M. Habermann W. Wang C. Theobalt ACM Transactions on Graphics 2019 (TOG) — Siggraph 2019 We propose a method for generating video-realistic animations of real humans under user control. [paper] [video] [talk] [bibtex] [project] |

|
Commodity RGB-D Sensors: Data Acquisition M. Zollhöfer RGB-D Image Analysis and Processing — Book Chapter Contributed chapter to a book on "RGB-D Image Analysis and Processing". We have a detailed look into the different types of existing range sensing technology and discuss common types of reconstruction errors. [paper] [bibtex] [project] |

|
Face2Face: Real-time Face Capture and Reenactment of RGB Videos J. Thies M. Zollhöfer M. Stamminger C. Theobalt M. Nießner Communications of the ACM 2019 — CACM 2019 (Research Highlight) Face2Face is an approach for real-time facial reenactment of a monocular target video sequence. [paper] [video] [bibtex] [project] |

|
LiveCap: Real-time Human Performance Capture from Monocular Video M. Habermann W. Xu M. Zollhöfer G. Pons-Moll C. Theobalt ACM Transactions on Graphics 2019 (TOG) — Siggraph 2019 We present the first real-time human performance capture approach that reconstructs dense, space-time coherent deforming geometry of entire humans in general everyday clothing from just a single RGB video. [paper] [video] [talk] [bibtex] [project] |

|
Mo²Cap²: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera W. Xu A. Chatterjee M. Zollhöfer H. Rhodin P. Fua H.-P. Seidel C.Theobalt IEEE Transactions on Visualization and Computer Graphics — IEEE VR 2019 We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. [paper] [video] [data] [talk] [bibtex] [project] |

|
High-Fidelity Monocular Face Reconstruction based on an Unsupervised Model-based Face Autoencoder A. Tewari M. Zollhöfer F. Bernard P. Garrido H. Kim P. Perez C. Theobalt Transactions on Pattern Analysis and Machine Intelligence — TPAMI 2018 In this work we propose a novel model-based deep convolutional autoencoder that addresses the highly challenging problem of reconstructing a 3D human face from a single in-the-wild color image. [paper] [bibtex] [project] |

|
NRST: Non-rigid Surface Tracking from Monocular Video M. Habermann W. Xu H. Rhodin M. Zollhöfer G. Pons-Moll C. Theobalt German Conference on Pattern Recognition — GCPR 2018 We propose an efficient method for non-rigid surface tracking from monocular RGB videos. [paper] [video] [talk] [bibtex] [project] |

|
Deep Video Portraits H. Kim P. Garrido A. Tewari W. Xu J. Thies M. Nießner P. Perez C. Richardt M. Zollhöfer C. Theobalt ACM Transactions on Graphics 2018 (TOG) — Siggraph 2018 We present a novel approach that enables full photo-realistic re-animation of portrait videos using only an input video. [paper] [video] [talk] [bibtex] [project] |

|
HeadOn: Real-time Reenactment of Human Portrait Videos J. Thies M. Zollhöfer C. Theobalt M. Stamminger M. Nießner ACM Transactions on Graphics 2018 (TOG) — Siggraph 2018 We propose HeadOn, the first real-time source-to-target reenactment approach for complete human portrait videos that enables transfer of torso and head motion, face expression, and eye gaze. [paper] [video] [talk] [bibtex] [project] |

|
State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications M. Zollhöfer J. Thies P. Garrido D. Bradley T. Beeler P. Perez M. Nießner M. Stamminger C. Theobalt Computer Graphics Forum 2018 — EG 2018 (STAR Report) This state-of-the-art report summarizes recent trends in monocular facial performance capture and discusses its applications, which range from performance-based animation to real-time facial reenactment. [paper] [talk] [bibtex] [project] |

|
State of the Art on 3D Reconstruction with RGB-D Cameras M. Zollhöfer P. Stotko A. Görlitz C. Theobalt M. Nießner R. Klein A. Kolb Computer Graphics Forum 2018 — EG 2018 (STAR Report) In this state-of-the-art report, we analyze the recent developments in RGB-D scene reconstruction in detail and review essential related work. [paper] [talk] [bibtex] [project] |

|
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz A. Tewari M. Zollhöfer P. Garrido F. Bernard H. Kim P. Perez C. Theobalt Proc. Computer Vision and Pattern Recognition 2018 — CVPR 2018 (Oral) We propose the first approach that jointly learns 1) a regressor for face shape, expression, reflectance and illumination on the basis of 2) a concurrently learned parametric face model. [paper] [supplemental] [video] [poster] [talk] [bibtex] [project] |

|
LIME: Live Intrinsic Material Estimation A. Meka M. Maximov M. Zollhöfer A. Chatterjee H.-P. Seidel C. Richardt C. Theobalt Proc. Computer Vision and Pattern Recognition 2018 — CVPR 2018 (Spotlight) We present the first end-to-end approach for real-time material estimation for general object shapes with uniform material that only requires a single color image as input. [paper] [supplemental] [video] [data] [poster] [bibtex] [project] |

|
InverseFaceNet: Deep Monocular Inverse Face Rendering H. Kim M. Zollhöfer A. Tewari J. Thies C. Richardt C. Theobalt Proc. Computer Vision and Pattern Recognition 2018 — CVPR 2018 (Poster) We introduce InverseFaceNet, a deep convolutional inverse rendering framework for faces that jointly estimates facial pose, shape, expression, reflectance and illumination from a single input image. [paper] [supplemental] [video] [poster] [bibtex] [project] |

|
MonoPerfCap: Human Performance Capture from Monocular Video W. Xu A. Chatterjee M. Zollhöfer H. Rhodin D. Mehta H.-P. Seidel C.Theobalt ACM Transactions on Graphics 2018 (TOG) — Siggraph 2018 We present the first marker-less approach for temporally coherent 3D performance capture of a human with general clothing from monocular video. [paper] [video] [data] [talk] [bibtex] [project] |
|
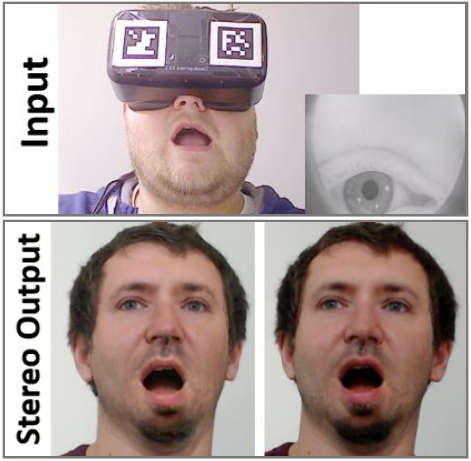
FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality J. Thies M. Zollhöfer M. Stamminger C. Theobalt M. Nießner ACM Transactions on Graphics 2018 (TOG) — Siggraph 2018 We introduce FaceVR, a novel method for gaze-aware facial reenactment in the Virtual Reality (VR) context. [paper] [video] [talk] [bibtex] [project] |

|
Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction A. Tewari M. Zollhöfer H. Kim P. Garrido F. Bernard P. Perez C. Theobalt Proc. of the International Conference on Computer Vision 2017 — ICCV 2017 (Oral) In this work we propose a novel model - based deep convolutional autoencoder that addresses the highly challenging problem of reconstructing a human face from a single image. [paper] [supplemental] [video] [talk] [bibtex] [project] |

|
Opt: A Domain Specific Language for Non-linear Least Squares Optimization in Graphics and Imaging Z. DeVito M. Mara M. Zollhöfer G. Bernstein J. Ragan-Kelley C. Theobalt P. Hanrahan M. Fisher M. Nießner ACM Transactions on Graphics 2017 (TOG) — Siggraph 2018 We propose a new language, Opt, in which a user simply writes energy functions over image- or graph-structured unknowns, and a compiler automatically generates state-of-the-art GPU optimization kernels. [paper] [code] [talk] [bibtex] [project] |

|
Live User-Guided Intrinsic Video for Static Scenes A. Meka G. Fox M. Zollhöfer C. Richardt C. Theobalt IEEE Transactions on Visualization and Computer Graphics — ISMAR 2017 We present a novel real-time approach for user-guided intrinsic decomposition of static scenes captured by an RGB-D sensor. [paper] [video] [data] [poster] [talk] [bibtex] [project] |

|
BundleFusion: Real-time Globally Consistent 3D Reconstruction using Online Surface Re-integration A. Dai M. Nießner M. Zollhöfer S. Izadi C. Theobalt ACM Transactions on Graphics 2017 (TOG) — SIGGRAPH 2017 We present the first marker-less approach for temporally coherent 3D performance capture of a human with general clothing from monocular video. [paper] [video] [data] [bibtex] [project] |
|
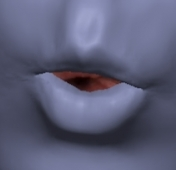
Corrective 3D Reconstruction of Lips from Monocular Video P. Garrido M. Zollhöfer C. Wu D. Bradley P. Perez T. Beeler C. Theobalt ACM Transactions on Graphics 2016 (TOG) — SIGGRAPH Asia 2016 We present a novel approach for fully automatic reconstruction of detailed and expressive lip shapes along with the dense geometry of the entire face, from just monocular RGB video. [paper] [supplemental] [video] [talk] [bibtex] [project] |
|
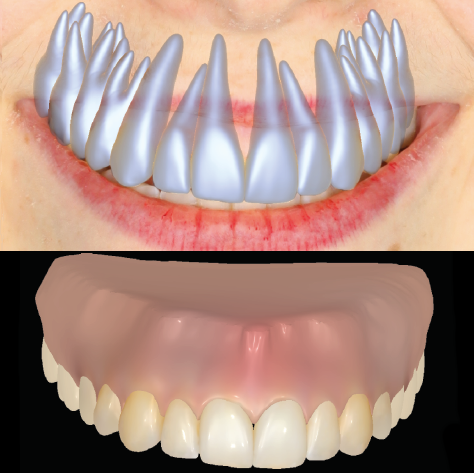
Model-Based Teeth Reconstruction C. Wu D. Bradley P. Garrido M. Zollhöfer C. Theobalt M. Gross T. Beeler ACM Transactions on Graphics 2016 (TOG) — SIGGRAPH Asia 2016 We present the first approach for non-invasive reconstruction of teeth from just a few input photographs. [paper] [video] [talk] [bibtex] [project] |

|
Real-time Halfway Domain Reconstruction of Motion and Geometry L. Thies M. Zollhöfer C. Richardt C. Theobalt G. Greiner Proc. of the International Conference on 3D Vision 2016 — 3DV 2016 We present a novel approach for real - time joint reconstruction of 3D scene motion and geometry from binocular stereo videos. [paper] [supplemental] [video] [poster] [bibtex] [project] |

|
Real-time Joint Tracking of a Hand Manipulating an Object from RGB-D Input S. Sridhar F. Mueller M. Zollhöfer D. Casas A. Oulasvirta C. Theobalt Proc. of the European Conference on Computer Vision 2016 — ECCV 2016 We propose a real-time solution for joint tracking of a hand and a manipulated object using only a single commodity RGB-D camera. [paper] [supplemental] [video] [data] [poster] [bibtex] [project] |

|
VolumeDeform: Real-time Volumetric Non-rigid Reconstruction M. Innmann M. Zollhöfer M. Nießner C. Theobalt M. Stamminger Proc. of the European Conference on Computer Vision 2016 — ECCV 2016 We present a novel approach for the reconstruction of dynamic geometric shapes using a single hand-held consumer-grade RGB-D sensor at real-time rates. [paper] [supplemental] [video] [data] [poster] [bibtex] [project] |

|
Live Intrinsic Video A. Meka M. Zollhöfer C. Richardt C. Theobalt ACM Transactions on Graphics 2016 (TOG) — Siggraph 2016 We present a novel variational approach to tackle the underconstrained intrinsic video decomposition problem at real-time frame rates enabling on-line processing of live video footage. [paper] [video] [data] [talk] [bibtex] [project] |

|
Face2Face: Real-time Face Capture and Reenactment of RGB Videos J. Thies M. Zollhöfer M. Stamminger C. Theobalt M. Nießner Proc. Computer Vision and Pattern Recognition 2016 — CVPR 2016 (Oral) We present a novel approach for real-time facial reenactment of a monocular target video sequence (e.g., Youtube video). The source sequence is also a monocular video stream, captured live with a commodity webcam. [paper] [supplemental] [video] [poster] [talk] [bibtex] [project] |

|
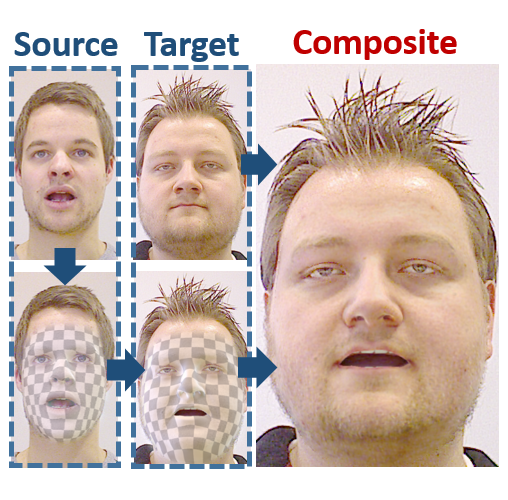
Reconstruction of Personalized 3D Face Rigs from Monocular Video P. Garrido M. Zollhöfer D. Casas L. Valgaerts K. Varanasi P. Perez C. Theobalt ACM Transactions on Graphics 2016 (TOG) — Siggraph 2016 We present a novel approach for the automatic creation of a personalized high-quality 3D face rig of an actor from just monocular video data, e.g. vintage movies. [paper] [supplemental] [video] [talk] [bibtex] [project] |
|
Real-time Expression Transfer for Facial Reenactment J. Thies M. Zollhöfer M. Nießner L. Valgaerts M. Stamminger C. Theobalt ACM Transactions on Graphics 2015 (TOG) — Siggraph Asia 2015 We present a method for the real-time transfer of facial expressions from an actor in a source video to an actor in a target video, thus enabling the ad-hoc control of the facial expressions of the target actor. [paper] [video] [talk] [bibtex] [project] |

|
Real-Time Pixel Luminance Optimization for Dynamic Multi-Projection Mapping C. Siegl M. Colaianni L. Thies J. Thies M. Zollhöfer S. Izadi M. Stamminger F. Bauer ACM Transactions on Graphics 2015 (TOG) — Siggraph Asia 2015 We present a real-time solution for smooth blending across multiple projectors using a new optimization framework that simulates the diffuse direct light transport of the physical world. [paper] [video] [bibtex] [project] |

|
Real-Time Reconstruction of Static and Dynamic Scenes M. Zollhöfer PhD Thesis (Published by Dr. Hut) — PhD Thesis (Published by Dr. Hut) We present new techniques and algorithms for building three-dimensional representations of arbitrary objects, manually editing the reconstructions and tracking their non-rigid motion at real-time rates. [paper] [talk] [bibtex] [project] |

|
Shading-based Refinement on Volumetric Signed Distance Functions M. Zollhöfer A. Dai M. Innmann C. Wu M. Stamminger C. Theobalt M. Nießner ACM Transactions on Graphics 2015 (TOG) — Siggraph 2015 We present a novel method to obtain fine-scale detail in 3D reconstructions generated with low-budget RGB-D cameras or other commodity scanning devices. [paper] [video] [data] [talk] [bibtex] [project] |

|
Low-Cost Real-Time 3D Reconstruction of Large-Scale Excavation Sites M. Zollhöfer C. Siegl M. Vetter B. Dreyer M. Stamminger S. Aybek F. Bauer Journal on Computing and Cultural Heritage 2015 — JOCCH 2015 The 3D reconstruction of archeological sites is expensive and a time-consuming task. In this article, we present a novel approach to 3D reconstruction and compare to a standard photogrammetry pipeline. [paper] [video] [bibtex] [project] |

|
Real-time Shading-based Refinement for Consumer Depth Cameras C. Wu M. Zollhöfer M. Nießner M. Stamminger S. Izadi C. Theobalt ACM Transactions on Graphics 2014 (TOG) — Siggraph Asia 2014 We present the first real-time method for refinement of depth data using shape-from-shading in general uncontrolled scenes. [paper] [video] [talk] [bibtex] [project] |

|
Interactive Model-based Reconstruction of the Human Head using an RGB-D Sensor M. Zollhöfer J. Thies M. Colaianni M. Stamminger G. Greiner Journal Computer Animation and Virtual Worlds 2014 — CASA 2014 We present a novel method for the interactive markerless reconstruction of human heads using a single commodity RGB-D sensor. [paper] [video] [talk] [bibtex] [project] |

|
Real-time Non-rigid Reconstruction using an RGB-D Camera M. Zollhöfer M. Nießner S. Izadi C. Rhemann C. Zach M. Fisher C. Wu A. Fitzgibbon C. Loop C. Theobalt M. Stamminger ACM Transactions on Graphics 2014 (TOG) — Siggraph 2014 We present a combined hardware and software solution for markerless reconstruction of non-rigidly deforming physical objects with arbitrary shape in real-time. [paper] [supplemental] [video] [talk] [bibtex] [project] |

|
Low-Cost Real-Time 3D Reconstruction of Large-Scale Excavation Sites using an RGB-D Camera M. Zollhöfer B. Riffelmacher M. Vetter B. Dreyer M. Stamminger F. Bauer EUROGRAPHICS Workshop on Graphics and Cultural Heritage 2014 — GCH 2014 In this paper, we present an end-to-end pipeline for the online reconstruction of large-scale excavation sites using an RGB-D camera. [paper] [video] [talk] [bibtex] [project] |

|
Real-time 3D Reconstruction at Scale using Voxel Hashing M. Nießner M. Zollhöfer S. Izadi M. Stamminger ACM Transactions on Graphics 2013 (TOG) — Siggraph Asia 2013 We contribute an online system for large and fine scale volumetric reconstruction based on a memory and speed efficient data structure. [paper] [video] [code] [talk] [bibtex] [project] |
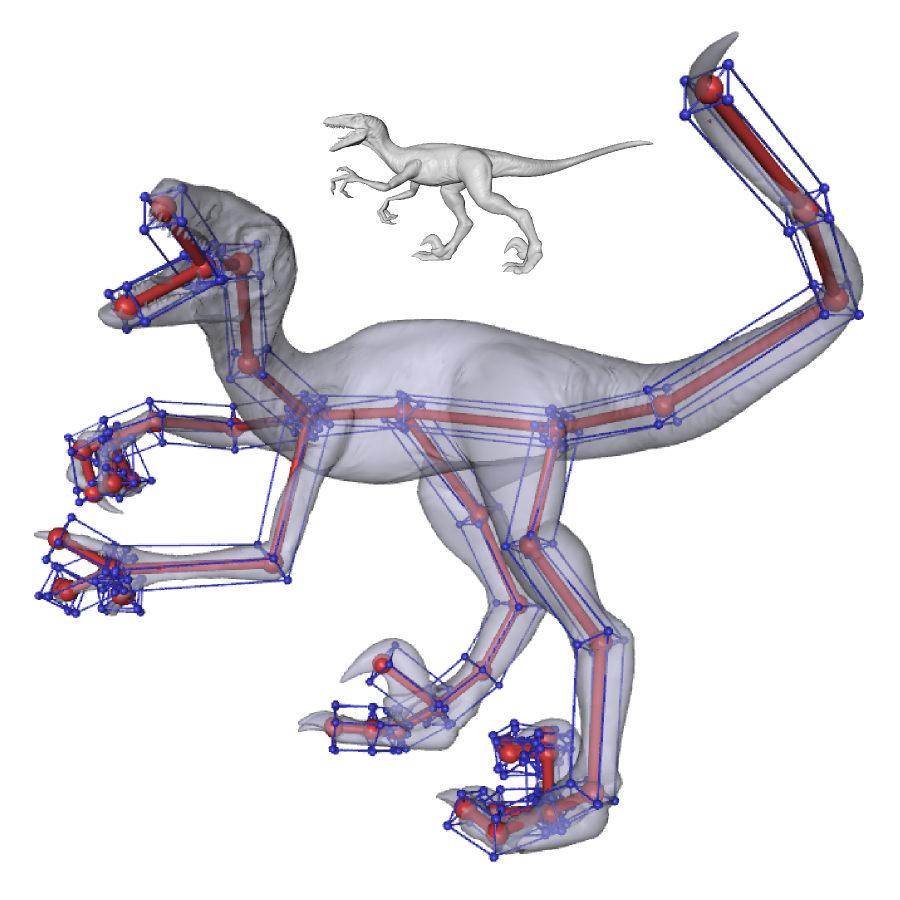
|
Pseudo-Skeleton based ARAP Mesh Deformation M. Zollhöfer A. Vieweg J. Süßmuth G. Greiner Proceedings of Computer Animation and Social Agents 2013 (Short Papers) — CASA 2013 In this work, we present a handle-based direct manipulation paradigm that builds upon a pseudo-skeleton with bones that are allowed to stretch and twist. [paper] [video] [talk] [bibtex] [project] |

|
Visualization and Deformation Techniques for Entertainment and Training in Cultural Heritage M. Zollhöfer J. Süßmuth F. Bauer M. Stamminger M. Boss Image and Signal Processing and Analysis 2013 — ISPA 2013 We think that state-of-the-art techniques in computer graphics and geometry processing can be leveraged in training and entertainment to make the topic of cultural heritage more accessible to a wider audience. [paper] [video] [talk] [bibtex] [project] |
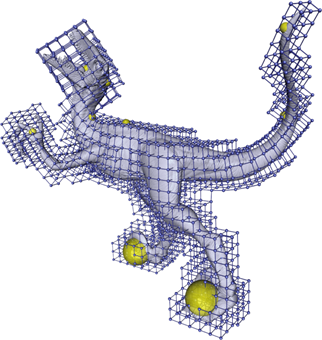
|
GPU based ARAP Deformation using Volumetric Lattices M. Zollhöfer E. Sert G. Greiner J. Süßmuth Eurographics 2012 (Short Papers) — EG 2012 We present a novel lattice based direct manipulation paradigm (LARAP) for mesh editing that decouples the runtime complexity from the mesh’s geometric complexity. [paper] [video] [talk] [bibtex] [project] |
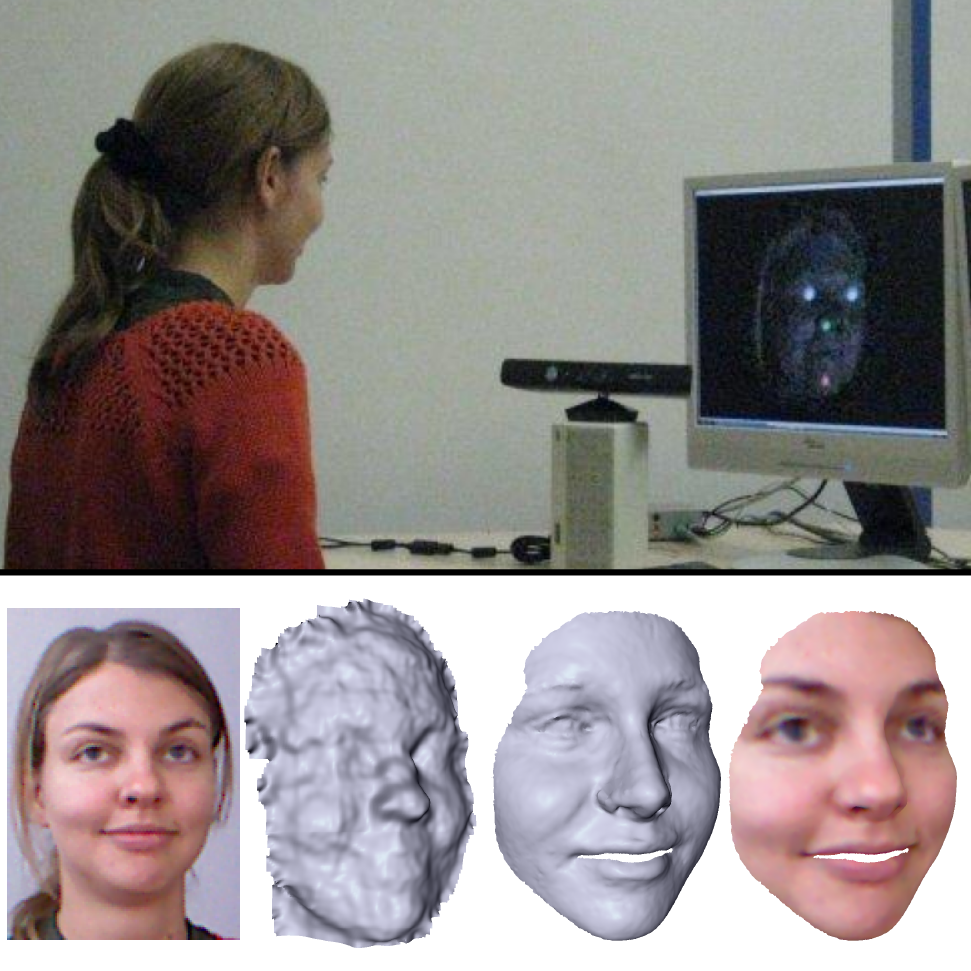
|
Automatic Reconstruction of Personalized Avatars from 3D Face Scans M. Zollhöfer M. Martinek G. Greiner M. Stamminger J. Süßmuth Journal Computer Animation and Virtual Worlds 2011 — CASA 2011 We present a simple algorithm for computing a high quality personalized avatar from a single color image and the corresponding depth map which have been captured by Microsoft’s Kinect sensor. [paper] [video] [talk] [bibtex] [project] |

|
Meshless Hierarchical Radiosity on the GPU M. Zollhöfer M. Stamminger Vision, Modeling, and Visualization 2011 — VMV 2011 In this paper, we analyze the bottlenecks of meshless radiosity and examine the possibilities for an efficient and parallel implementation on the GPU. [paper] [video] [poster] [talk] [bibtex] [project] |
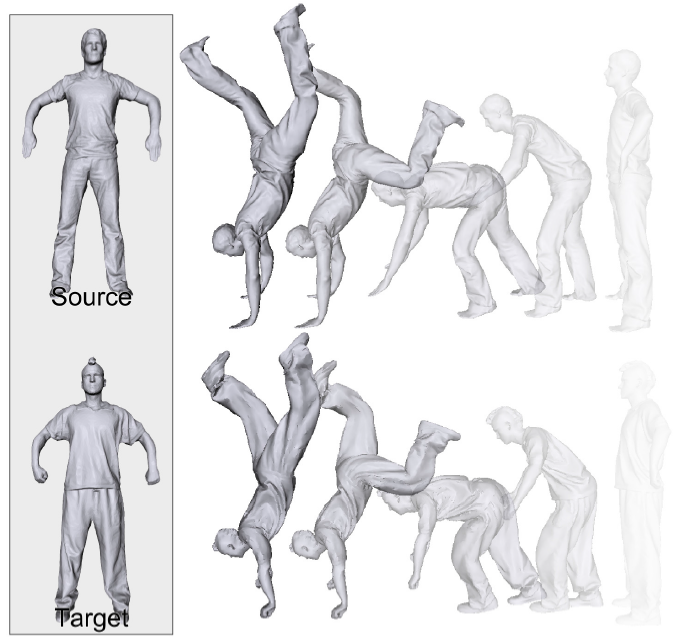
|
Animation Transplantation J. Süßmuth M. Zollhöfer G. Greiner Journal Computer Animation and Virtual Worlds 2010 — CASA 2010 We present a novel method to animate a static geometry by cloning a captured animation sequence. [paper] [video] [bibtex] [project] |